یک اشتباه کوچک در فایل robots.txt میتواند باعث شود گوگل نتواند صفحات مهم سایت شما را بخزد و در نتیجه رتبههایتان افت کند. اما اگر این فایل بهدرستی تنظیم شود، به مدیریت خزش، بهینهسازی سئو فنی و جلوگیری از ایندکس شدن صفحات غیرضروری کمک میکند.
در این مقاله دقیق و کاربردی بررسی میکنیم:
اگر میخواهید بدانید فایل robots.txt سایت شما دقیقاً چه نقشی در سئو دارد، ادامه این راهنما را از دست ندهید.

به زبان ساده، robots.txt یک فایل متنی است که به موتورهای جستجو میگوید کدام بخشهای سایت را بخزند و کدام بخشها را نادیده بگیرند.
این فایل قبل از اینکه خزندهای مانند Googlebot شروع به بررسی صفحات کند، ابتدا آن را میخواند و آدرس آن به شکل زیر است:
https://example.com/robots.txtاگر فایل robots.txt سایت وجود نداشته باشد، گوگل بهصورت پیشفرض اجازه خزش تمام صفحات را دارد.
نکته کلیدی که باید همین ابتدا روشن شود این است: فایل robots.txt برای کنترل خزش (Crawl) استفاده میشود، نه برای کنترل ایندکس (Index).
بسیاری از مدیران سایتها تصور میکنند اگر صفحهای را در فایل روبوتس مسدود کنند، آن صفحه از نتایج گوگل حذف میشود؛ در حالی که این تصور کاملاً درست نیست.
برای درک بهتر، این تفاوت را ببینید:
اگر صفحهای را با دستور Disallow در فایل robots.txt مسدود کنید:
| موضوع | Crawl (خزش) | Index (ایندکس) |
| معنی | بررسی و خواندن صفحه توسط ربات موتور جستجو | ذخیره شدن صفحه در پایگاه داده گوگل و امکان نمایش در نتایج |
| قابل کنترل با robots.txt | بله | خیر |
| قابل کنترل با meta noindex | خیر | بله |
به همین دلیل، فایل robots.txt برای حذف صفحات از نتایج گوگل ابزار مناسبی نیست و در چنین شرایطی باید از meta noindex یا ابزار حذف URL در سرچ کنسول استفاده شود.
کاربرد اصلی فایل robots.txt سایت شامل موارد زیر است:
تنظیم صحیح این فایل یکی از پایههای مهم در سئو تکنیکال محسوب میشود و اشتباه در آن میتواند ساختار خزش کل سایت را مختل کند.
فایل robots.txt باید در ریشه سایت (Root Directory هاست) قرار بگیرد؛ یعنی همان پوشه اصلی که دامنه به آن متصل است و سایت از آن بارگذاری میشود. در اغلب هاستها این مسیر پوشهای مانند public_html یا www است.
این فایل باید دقیقاً در آدرس زیر در دسترس باشد:
https://example.com/robots.txtاگر فایل در پوشه دیگری قرار داشته باشد (مثلاً داخل blog یا wp-content)، موتورهای جستجو آن را شناسایی نخواهند کرد.
برای بررسی وجود فایل روبوتس، کافی است /robots.txt را به انتهای دامنه اضافه کنید. اگر فایل نمایش داده شد یعنی فعال است؛ اگر خطای 404 دریافت کردید، یعنی فایل وجود ندارد. در صورت نبود فایل، گوگل بهصورت پیشفرض اجازه خزش تمام صفحات سایت را خواهد داشت.
برای ایجاد فایل robots.txt مراحل زیر را انجام دهید:
نام فایل باید دقیقاً با حروف کوچک نوشته شود؛ در غیر این صورت ممکن است توسط رباتها شناسایی نشود.
در سایتهای وردپرسی، وضعیت فایل robots.txt کمی متفاوت است.
در حالت پیشفرض، وردپرس ممکن است یک فایل robots.txt مجازی تولید کند. این فایل زمانی نمایش داده میشود که فایل فیزیکی در هاست وجود نداشته باشد. اما این حالت کنترل محدودی دارد و برای مدیریت حرفهای فایل robots.txt سایت توصیه نمیشود.
برای کنترل دقیقتر، دو راه دارید:
در پروژههایی که ساختار سایت پیچیده است، مانند فروشگاههای ووکامرس یا سایتهای محتوایی بزرگ بهتر است فایل robots.txt وردپرس بهصورت فیزیکی در هاست مدیریت شود تا کنترل کاملتری بر خزش صفحات وجود داشته باشد.
در سایتهای وردپرسی، robots.txt فقط یک فایل ساده نیست؛ این تنظیمات باید با وضعیت افزونههای سئو، صفحات آرشیو، دستهبندیها، برگههای مهم و مسیر ایندکس سایت هماهنگ باشد. به همین دلیل، در پروژههای حرفهای، بررسی فایل روبوتس بخشی از مسیر سئو سایت وردپرسی محسوب میشود.
هر سابدامین فایل robots.txt جداگانه دارد. یعنی:
example.com
blog.example.com
shop.example.com
هرکدام نیاز به فایل robots.txt مستقل دارند و تنظیم فایل در دامنه اصلی، روی سابدامینها تأثیری ندارد. این موضوع در بسیاری از پروژههای سئو نادیده گرفته میشود و میتواند باعث اختلال در مدیریت خزش شود.
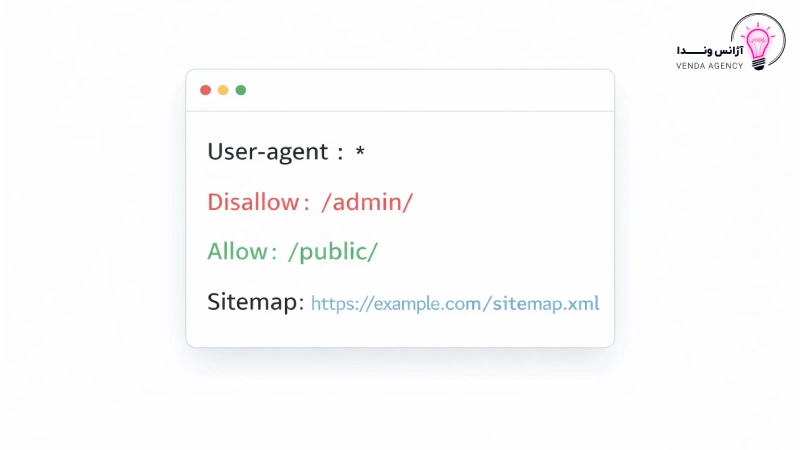
ساختار فایل robots.txt بسیار ساده است، اما همین سادگی باعث میشود کوچکترین اشتباه، تأثیر بزرگی روی سئو سایت بگذارد.
هر قانون در فایل روبوتس معمولاً از دو بخش تشکیل میشود:
در ادامه، مهمترین دستورات فایل robots.txt سایت را بررسی میکنیم.
این دستور مشخص میکند قانون برای کدام ربات موتور جستجو اعمال شود.
اگر بخواهید قانون برای تمام رباتها اعمال شود، از علامت ستاره استفاده میکنید:
User-agent: *
اگر بخواهید فقط برای گوگل اعمال شود:
User-agent: Googlebot
در اکثر سایتها، استفاده از * کافی است مگر اینکه بخواهید رفتار خاصی برای یک ربات خاص تعریف کنید.
این دستور به ربات میگوید کدام مسیر را نخزد.
مثال:
User-agent: *
Disallow: /wp-admin/
در این حالت، تمام رباتها از خزش پوشه wp-admin منع میشوند.
اگر بخواهید کل سایت را ببندید (که معمولاً اشتباه مرگبار است):
User-agent: *
Disallow: /
این دستور یعنی هیچ صفحهای اجازه خزش ندارد.
گاهی لازم است یک پوشه را ببندید، اما اجازه دهید فایل خاصی داخل آن خزیده شود.
مثال رایج در فایل robots.txt وردپرس:
User-agent: *
Disallow: /wp-admin/
Allow: /wp-admin/admin-ajax.php
در این حالت، کل پوشه wp-admin بسته است، اما فایل admin-ajax.php اجازه خزش دارد.
میتوانید مسیر نقشه سایت را داخل فایل robots.txt سایت معرفی کنید:
Sitemap: https://example.com/sitemap.xml
این دستور الزامی نیست، اما به موتورهای جستجو کمک میکند سریعتر ساختار صفحات شما را شناسایی کنند.
در پروژههای حرفهای سئو فنی، معمولاً هم از ثبت سایت مپ در Search Console استفاده میشود و هم از معرفی آن در فایل روبوتس.
برخی منابع به دستور زیر اشاره میکنند:
Crawl-delay: 10
این دستور برای تعیین فاصله زمانی بین درخواستهای ربات طراحی شده است، اما نکته مهم اینجاست:
گوگل از Crawl-delay پشتیبانی نمیکند.
بنابراین اگر هدف شما مدیریت نرخ خزش Googlebot است، باید از تنظیمات سرچ کنسول یا بهینهسازی ساختار سایت استفاده کنید، نه این دستور.
درک صحیح این دستورات، پایهای برای مدیریت حرفهای فایل robots.txt سایت است و نقش مهمی در بهینهسازی سئو داخلی و ساختار خزش دارد.
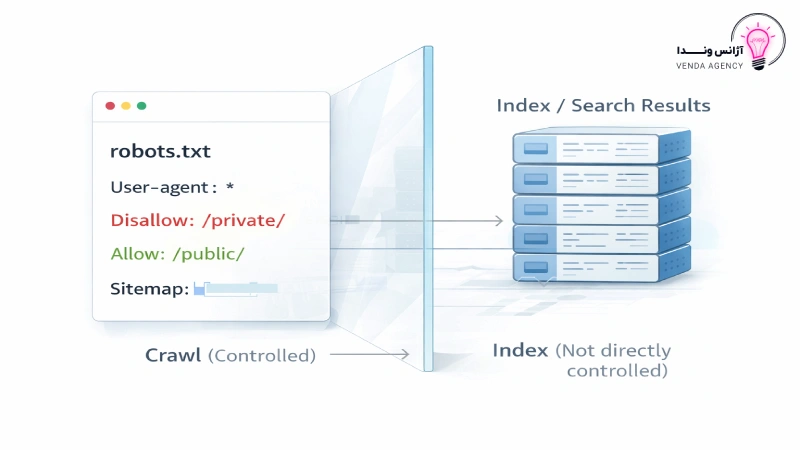
یکی از رایجترین دلایل آسیب دیدن سئو سایتها، استفاده نادرست از فایل robots.txt است. بسیاری از مدیران سایت تصور میکنند این فایل میتواند هر نوع محدودسازی یا حذف صفحه را مدیریت کند، در حالی که چنین نیست.
مهمترین محدودیتهای فایل robots.txt سایت عبارتاند از:
درک این محدودیتها باعث میشود هنگام تنظیم فایل robots.txt وردپرس یا سایر سایتها، دچار تصمیمهای اشتباه و پرهزینه نشوید.
تا اینجا فهمیدیم فایل robots.txt چیست، چه دستورات اصلی دارد و چه محدودیتهایی دارد. حالا ببینیم در عمل، فایلrobots.txt سایت در پروژههای مختلف چگونه تنظیم میشود.
توجه داشته باشید این نمونهها عمومی هستند و باید متناسب با ساختار URL هر سایت شخصیسازی شوند.
در سایتهای شرکتی معمولاً فقط نیاز است دسترسی به بخش مدیریت مسدود شود و مسیر نقشه سایت معرفی گردد:
User-agent: *
Disallow: /wp-admin/
Allow: /wp-admin/admin-ajax.php
Sitemap: https://example.com/sitemap.xmlاین ساختار برای اغلب سایتهای وردپرسی استاندارد است و پایهی تنظیم فایلrobots.txt وردپرس محسوب میشود.
در فروشگاههای اینترنتی، صفحات خاصی مانند سبد خرید، تسویه حساب یا حساب کاربری نیازی به خزش ندارند:
User-agent: *
Disallow: /cart/
Disallow: /checkout/
Disallow: /my-account/
Disallow: /?s=
Allow: /wp-admin/admin-ajax.php
Sitemap: https://example.com/sitemap.xmlچرا این مسیرها مسدود میشوند؟
در سایتهای خبری یا وبلاگهای گسترده، معمولاً تمرکز روی مدیریت پارامترها و فیلترهاست:
User-agent: *
Disallow: /*?replytocom=
Disallow: /search/
Disallow: /tag/
Allow: /wp-admin/admin-ajax.php
Sitemap: https://example.com/sitemap.xmlدر این حالت:
اینجاست که تصمیمگیری تخصصی اهمیت پیدا میکند. در برخی سایتها، صفحات تگ بخشی از استراتژی سئو داخلی هستند و نباید مسدود شوند. بنابراین نسخه نهایی فایل روبوتس باید با تحلیل ساختار سایت تعیین شود، نه با کپیکردن از یک نمونه آماده.
چند نکته مهم قبل از کپی کردن نمونهها
در پروژههای حرفهای که در قالب خدمات سئو انجام میشوند، تنظیم فایل robots.txt سایت همیشه بر اساس تحلیل Crawl و دادههای سرچ کنسول صورت میگیرد، نه بر اساس نسخههای عمومی.

اگر تنظیم فایل robots.txt سایت بدون دقت انجام شود، ممکن است خزندههای گوگل به صفحات مهم دسترسی نداشته باشند یا منابع حیاتی سایت (مثل CSS/JS) را نبینند. مهمترین اشتباهات عبارتاند از:
User-agent: *
Disallow: /
اگر بعد از انتشار سایت این دستور باقی بماند، عملاً گوگل اجازه خزش هیچ صفحهای را ندارد.
تنظیم فایل robots.txt بدون بررسی در سرچ کنسول، یک ریسک جدی در سئو فنی محسوب میشود. حتی اگر قوانین را درست نوشته باشید، ممکن است بهدلیل خطای تایپی، مسیر اشتباه یا تنظیمات سرور، خزش سایت مختل شود.
در ادامه مهمترین روشهای بررسی و عیبیابی فایل robots.txt سایت را مرور میکنیم.
اگر در بخش Indexing → Pages در سرچ کنسول با وضعیت Blocked by robots.txt مواجه شدید، یعنی گوگل قصد خزش صفحهای را داشته اما طبق قوانین فایل روبوتس اجازه دسترسی نداشته است.
در این حالت:
این اتفاق معمولاً زمانی رخ میدهد که بدون بررسی دقیق، یک مسیر کلی Disallow شده باشد.
اگر گوگل نتواند فایل robots.txt سایت را دریافت کند، در گزارشها خطای robots.txt unreachable نمایش داده میشود.
دلایل رایج:
در این شرایط، گوگل موقتاً رفتار پیشفرض را اعمال میکند، اما اگر مشکل ادامهدار باشد، میتواند روی خزش سایت اثر منفی بگذارد.
قبل از اینکه مسیر مهمی را در فایل robots.txt وردپرس یا هر سایت دیگری مسدود کنید، بهتر است URL آن صفحه را در ابزار URL Inspection بررسی کنید.
مراحل پیشنهادی:
این کار از بسیاری از اشتباهات پرهزینه جلوگیری میکند.
هر بار که فایل robots.txt سایت را ویرایش میکنید:
در پروژههای حرفهای سئو، هر تغییر در فایل روبوتس با دادههای Crawl و گزارشهای سرچ کنسول تحلیل میشود؛ نه صرفاً بر اساس حدس یا تجربه قبلی.
یک نکته مهم: گاهی افت رتبه بهخاطر الگوریتم یا محتوا نیست؛ بلکه یک خط اشتباه در فایل robots.txt سایت باعث شده گوگل نتواند صفحات کلیدی را بخزد. به همین دلیل، بررسی دورهای فایل روبوتس بخشی از چکلیست استاندارد سئو فنی محسوب میشود.
در این مقاله، بهطور کامل بررسی کردیم که فایلrobots.txt چیست و چگونه میتوان آن را برای مدیریت خزش سایت بهطور مؤثر استفاده کرد. همچنین، اشتباهات رایج در استفاده از این فایل را بیان کردیم تا از هرگونه تأثیر منفی بر سئو سایت جلوگیری شود.
یاد داشته باشید که فایل robots.txt یک ابزار ضروری برای مدیریت خزش است، اما باید با دقت و توجه به جزئیات تنظیم شود تا صفحات مهم سایت از دسترس رباتها خارج نشوند.
برای مشاوره در زمینه سئو فنی و بهینهسازی فایلهای robots.txt، تیم آژانس دیجیتال مارکتینگ وندا آمادهی کمک به شماست. اگر نیاز به مشاوره سئو یا سایر خدمات دیجیتال مارکتینگ دارید، همین حالا با ما تماس بگیرید.